Local e-ink handwriting recognition with on-device VLMs
For decades, I've carried a Field Notes notebook and a pen. I mainly used them to capture ideas on the go, but it would also be great to sketch out a diagram, or to journal a little bit, especially while traveling.
Fast note-taking via the iPhone's action button has alleviated a lot of my need for quickly capturing ideas. But nothing can replace pen and paper for long form stream-of-consciousness writing or diagramming.
I wanted to give my writing a digital life alongside the rest of my notes. So a year ago, I bought an A5 e-ink writer called Supernote. I really like it so far: it's a good size, input latency is reasonable, and the overall writing experience is fine. The device provides real-time text recognition on-device and a modest cloud syncing service. I've been using their unofficial API to sync notes and bring them into my Obsidian inbox. But then something happened...
- I wrote quite a bit on the Supernote during my trip to Patagonia, and came back to realize that the on-device recognizer has a pretty high error rate.
- Supernote Cloud enabled mandatory two-factor authentication. This broke my programmatic access to their cloud. So much for "unofficial but stable".
- The quality of handwriting recognition using Vision Language Models (VLMs) has skyrocketed, including for models capable of running locally on a modern Mac.
Measuring handwriting recognition accuracy
Just three weeks ago (November 2025), someone released OCR Arena, a knockoff of LM Arena but for comparing VLMs in their OCR abilities. AI is moving so quickly, as soon as you have a cool idea, someone's just done it!
OCR Arena compares the latest crop of VLMs but obviously does not include Supernote's on-device handwriting recognizer, nor does it include previous generation OCR libraries. I wanted a more broad-based multi-way comparison specific to my scenario. How well do the various approaches work on my handwriting on this device? I set out to compare a few different approaches to this problem:
- A state-of-the-art cloud model (e.g. Anthropic's
claude-opus-4-5-20251101) - A state-of-the-art open weights VLM capable of running on my stock Mac Mini M4 (e.g.
qwen3-vl:8b) - The real-time handwriting recognition engine which runs on the Supernote e-ink writer device.
- Traditional, pre-LLM OCR systems. (I realize tesseract is not the best for this, but still an interesting baseline.)
I put together a tiny evaluation set which included five handwritten pages from my Patagonian journal, and manually transcribed them for ground truth. Claude and I built a small evaluation script for transcribing the examples in the dataset and comparing Word Error Rates (WER) across them.
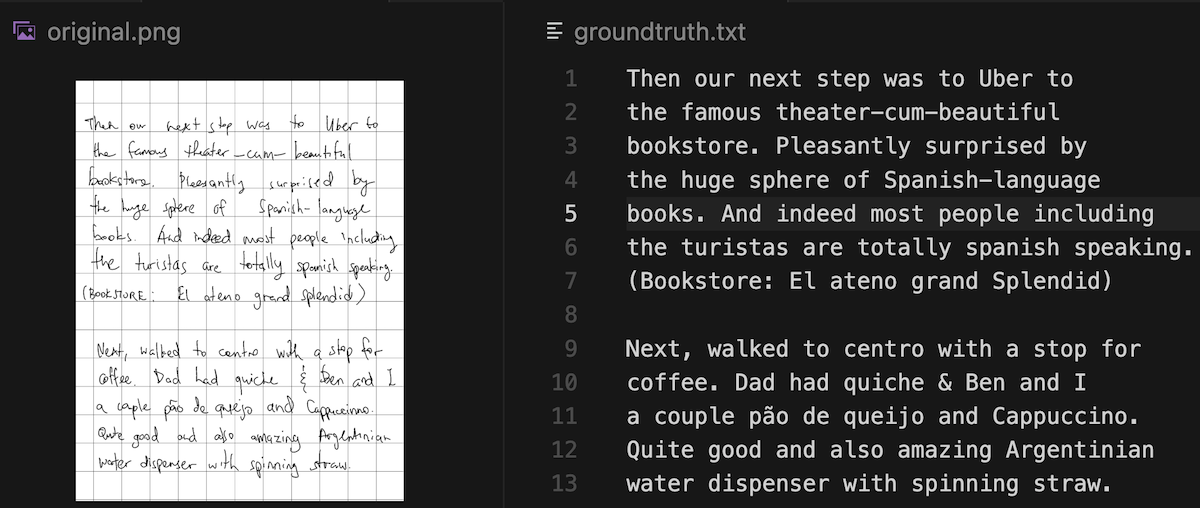
To make this concrete, here's a page I wrote from my travel log and the ground truth I manually transcribed:
And here's a side-by-side comparison of the transcript produced by qwen3-vl:8b, Supernote's on-device model, and tesseract:
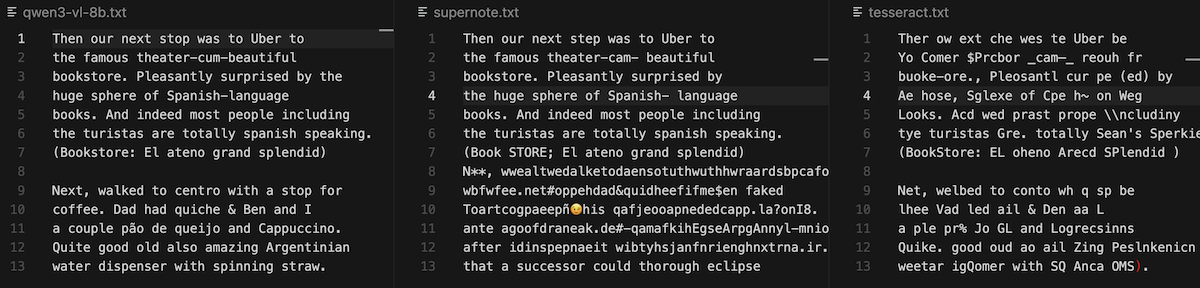
As you can see, tesseract produces terrible output. This is not surprising, since it's not trained for handwritten text but printed text. To do this right, you'd need to retrain it with a corpus of handwritten documents, but I still wanted to include it as a baseline.
Supernote's real-time on-device handwriting recognizer does reasonably well sometimes, but other times goes off the rails, as you can see in the example above. For the curious, code for these benchmark scripts is available.
Calculating word error rates and aggregating all the pages' WER scores resulted in the following table:
| Model | WER Mean | Latency Mean |
|---|---|---|
| claude-opus-4-5-20251101 | 0.0308 | 6.17s |
| qwen3-vl:8b | 0.0514 | 74.13s |
| supernote | 0.2731 | N/A |
| tesseract | 0.9533 | 0.57s |
Improving qwen3-vl:8b with a bit of prompting
Surprisingly, the prompt given to qwen3-vl:8b matters quite a bit. My initial prompt was:
prompt = "Extract all text from this handwritten note. Return only the transcribed text in markdown format, without any additional commentary or formatting."
With this basic prompt, qwen3-vl:8b would get stuck in a thinking loop and return an empty transcript at all about a quarter of the time. This failure mode would take hundreds of seconds and eventually end up repeating the same word dozens of times and then timing out.
After some experimentation with prompt and other parameters, I found empirically that updating the prompt seemed to reduce this rate to almost zero:
prompt = """You are an OCR engine, not a writing assistant.
Task:
- Read the handwritten note in the image.
- Output the exact transcription of the text as plain markdown.
Critical constraints:
- Do NOT explain what you are doing.
- Do NOT think step-by-step.
- Do NOT describe, analyze, or comment on the note.
- Do NOT use phrases like "let's", "wait", "first line", "next line", "line X", "Got it", or "step by step".
- Do NOT mention spellings or say how words are written.
- Do NOT repeat any single word more than twice in a row.
- If you notice yourself repeating a word or phrase, immediately stop and output your best single transcription of the whole note.
- Your entire response must be ONLY the final transcription text, nothing else."""
Integration into my System for Thought
Now that I had some metrics for word error rates across various approaches, I was able to make an informed decision driven by these considerations:
- Privacy > everything. Privacy preservation is extremely important to me as I'm journalling about potentially very personal topics. I don't want my journal in anyone's training set.
- Accuracy > latency. Supernote's on-device transcription is handy, but I'm mostly not in a hurry. I'd happily trade speed for higher quality transcription.
I went with qwen3-vl:8b. It takes about a minute to process a page on my $450 Mac Mini. The word error rate is about 5% which is not far from the best possible results of 3% via Claude's high-end model.
Handwriting transcription is now implemented in my note-vault-utilities, a suite of scripts that garden my plaintext note corpus. Cloud sync to desktop is achieved using the Supernote Mac app and my daily note cron job picks up and transcribes any new handwritten notes into the Obsidian note corpus.