CrowdForge: crowdsourcing complex tasks
Work marketplaces like MTurk are great for accomplishing small, well defined nuggets of work, such as labeling images and transcribing audio, but terrible for many more complex and labor intensive real world tasks. Over the last year, Robert Kraut, Niki Kittur and I formalized a general process of solving such complex problems using MTurk. We proposed three basic types of tasks and explored them in two neat experimental applications. To facilitate these experiments, I implemented CrowdForge, a Django framework that takes output from MTurk HITs and uses it to create new MTurk HITs.
Solving complex problems on MTurk has always involved partitioning the complex task into simpler sub-tasks. CastingWords, one of the most popular MTurk requesters, transcribes long audio recordings by splitting them into overlapping segments, distributing the work among workers, performing quality control and then recombining the transcription fragments. CrowdForge formalizes this approach and takes it to the next level. CrowdForge proposes the following task breakdown, roughly inspired by the MapReduce programming paradigm:
- partition tasks split a problem into sub-problems (one to many)
- map tasks solve a small unit of work (one to one)
- reduce tasks combine multiple results into one (many to one)
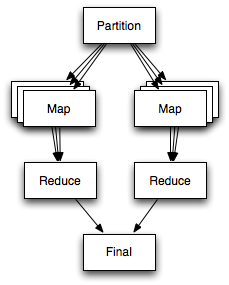
CastingWords uses human intelligence only for their map tasks, which consist of transcribing speech samples to text. Their partition task may involve an algorithm which seeks natural breaks in speech audio samples, while the reduce task may involve programmatic stitching of audio samples. For sufficiently complex cases, however, algorithms may be inadequate, and the partitioning and reduction require human intelligence. Here are some experiments that illustrate this idea:
Writing Articles
In the first experiment, turkers generated encyclopedia-style articles on a given subject. The approach I took was to first generate an article outline using an partition task, then for each heading in the outline, to collect facts on the topic, next to combine these facts into a paragraph, finally merging all of the paragraphs into a final article. The following diagram illustrates this process for an article on New York City:
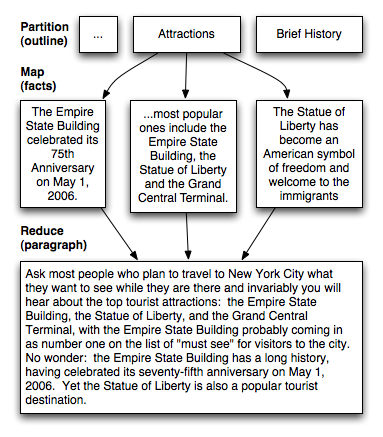
In one incarnation of this experiment, we used this approach to create five articles about New York City. Articles cost an average of $3.26 to produce, required an average of 36 subtasks or HITs, included an average of 5.3 topics per article and consisted of an average of 658 words. As a comparison baseline, we created eight HITs which each requested one worker to write the full article, paying $3.26, the same amount required for the collaboratively written articles.
We then evaluated the quality of all articles by asking a new set of workers to each rate a single article based on use of facts, spelling and grammar, article structure, and personal preference. On average the articles produced by the group were of rated on par with the Simple Wikipedia article on the same topic, and higher than those produced individually. See the paper for gritty details on the stats.
Product Comparisons
We did another experiment to prove the generality of the approach. We used CrowdForge to create purchase decision matrices to assist consumers looking to buy a new car. Given a short description of a consumer need, we created two partition tasks: one to decide which cars might be appropriate to consider, and one to decide which features the consumer cares most about. This double partition resulted in an empty product comparison chart. Each cell in the chart then spawned a map task to collect related facts. Next, these facts are reduced into a sentence, resulting in a product comparison chart. Here's an excerpt:
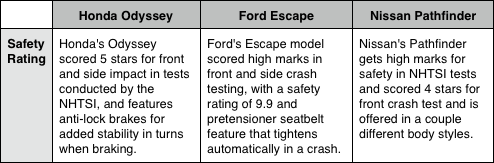
The entire task was completed in 54 different HITs for a total cost of $3.70. When we tried to compare to the individual case, we had no success getting individuals to generate a similar product comparison chart, even when offering more money than we paid the entire group.
Sweet Applications
MTurk is a one of my favorite tools for doing creative and novel projects. As illustrated, applying human intelligence to reduce and partition tasks, we can solve a new set of interesting problems. But there is much more to explore! For example, imagine collaborative drawing assignments in which a worker sketches out a picture, and subsequent workers refine the original picture by drawing sub-pictures or specific objects. Imagine requesting a trip plan and getting a researched day-by-day itinerary of what to see and do. Imagine partitioning a Java class into methods, outsourcing the implementation and unit test implementations.
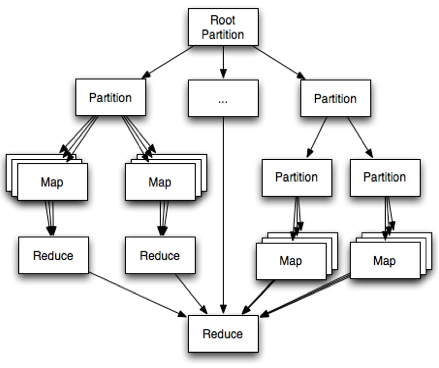
CrowdForge is written as a Django application that communicates with MTurk servers using the Boto interface, which is a Python framework that encapsulates the Amazon Web Services API. CrowdForge regularly polls MTurk and fires notifications whenever interesting things happen (a new result comes in for a HIT, all HITs of a certain type are finished, a HIT is expired or complete). CrowdForge can manage many flows, which encapsulate code that determines how to respond to these events. For example, the article writing flow knows to create fact collection HITs for each outline topic once the outline is submitted. So to solve a new kind of complex problem, you would extend CrowdForge with a custom flow, like the following:
"But Boris", you say, "how can I get my hands on this CrowdForge framework of yours?" Indeed, we just released it for non-commercial use under the Creative Commons license. Let me know if you have any questions, comments or interest in collaborating or maintaining the framework.
Update (February 2011): CrowdForge was covered in NewScientist, in a CMU article, and in a NY Times blog.
Update (November 2011): The full paper was presented at UIST 2011 in Santa Barbara.